|
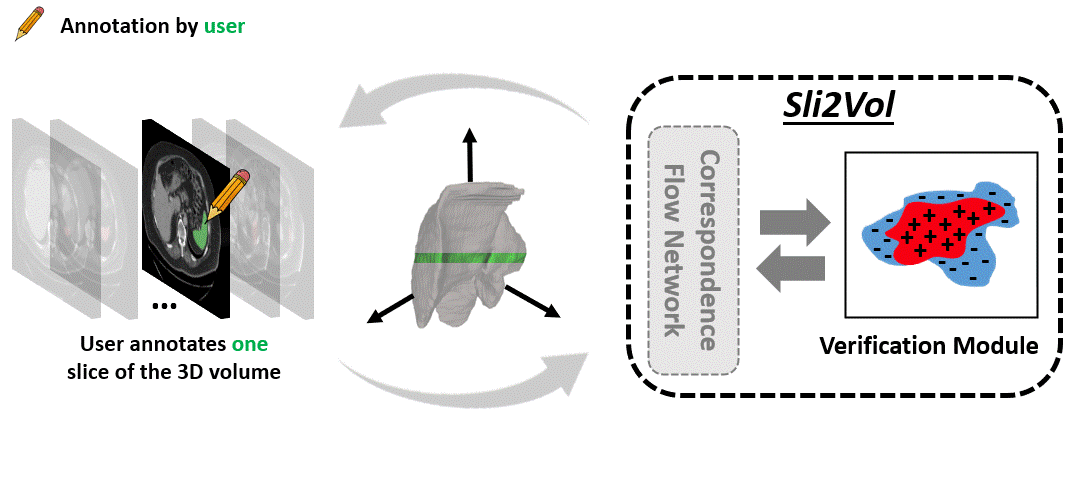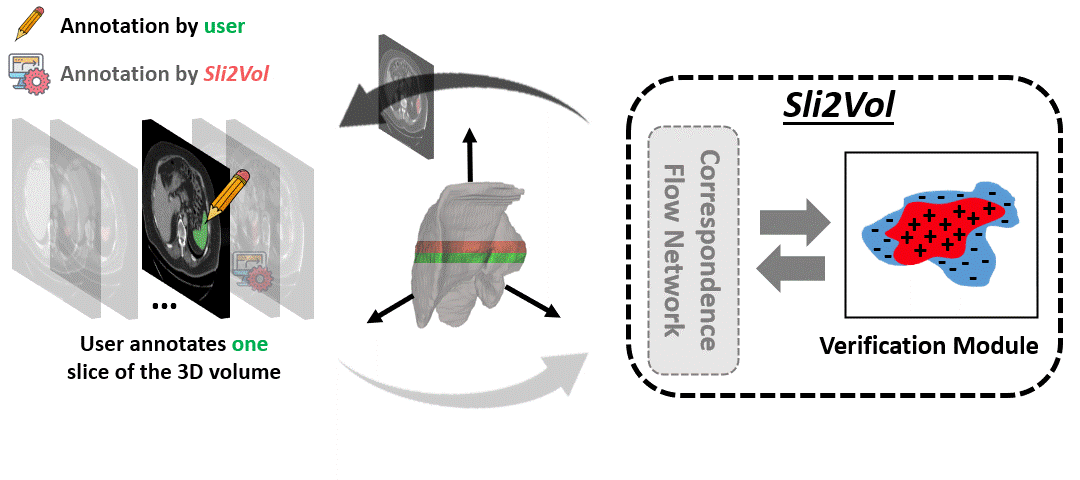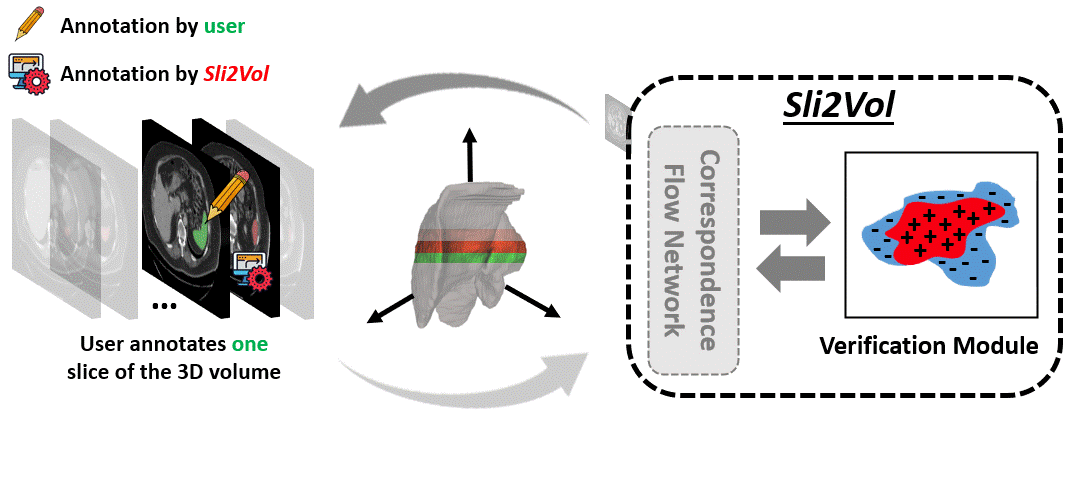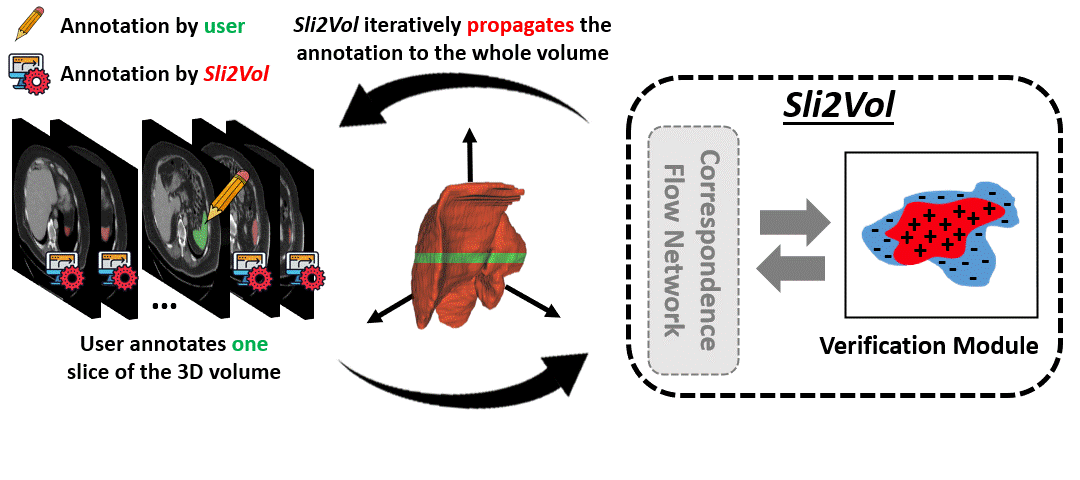
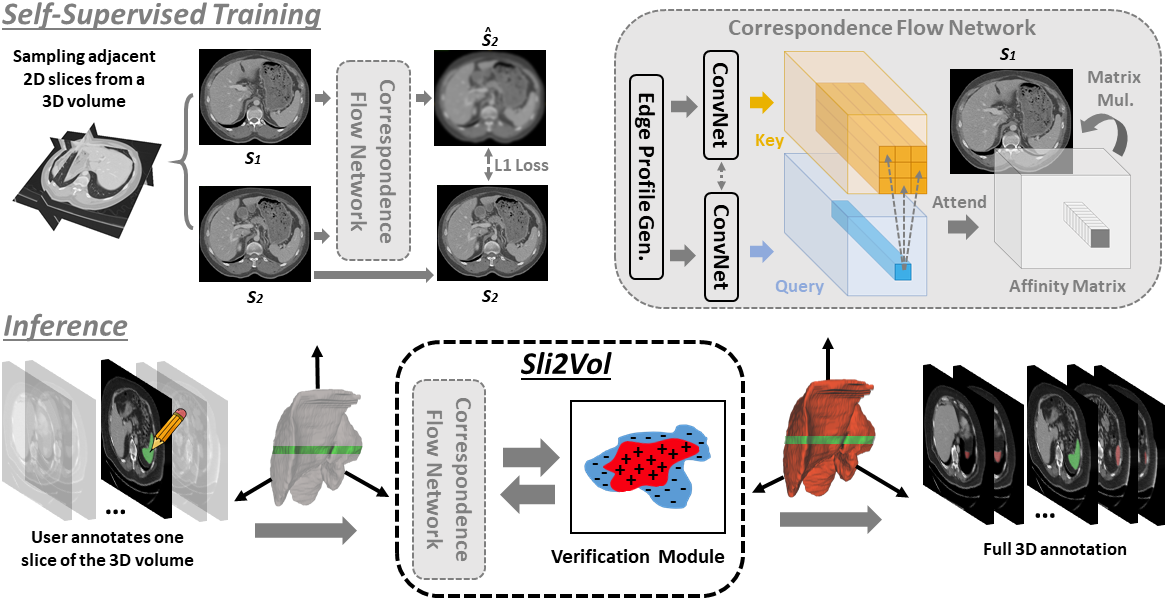
The objective of this work is to segment any arbitrary structures of interest (SOI) in 3D volumes by only annotating a single slice,
(i.e. semi-automatic 3D segmentation).
We show that high accuracy can be achieved by simply propagating the 2D slice segmentation
with an affinity matrix between consecutive slices, which can be learnt in a self-supervised manner,
namely slice reconstruction.
Specifically, we compare the proposed framework, termed as Sli2Vol,
with supervised approaches and two other unsupervised/ self-supervised slice registration approaches,
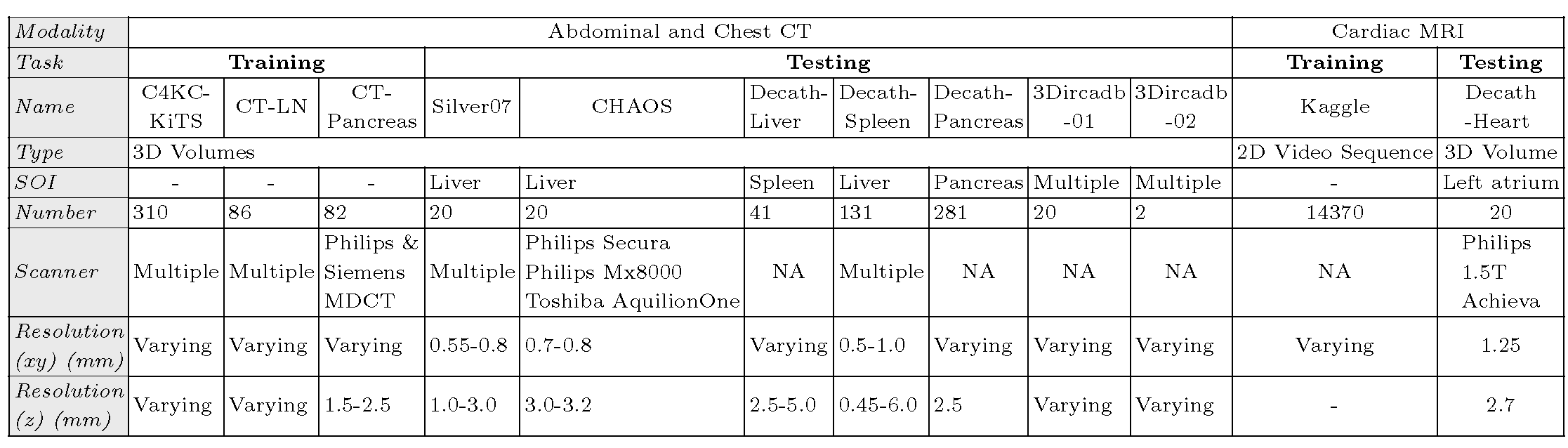
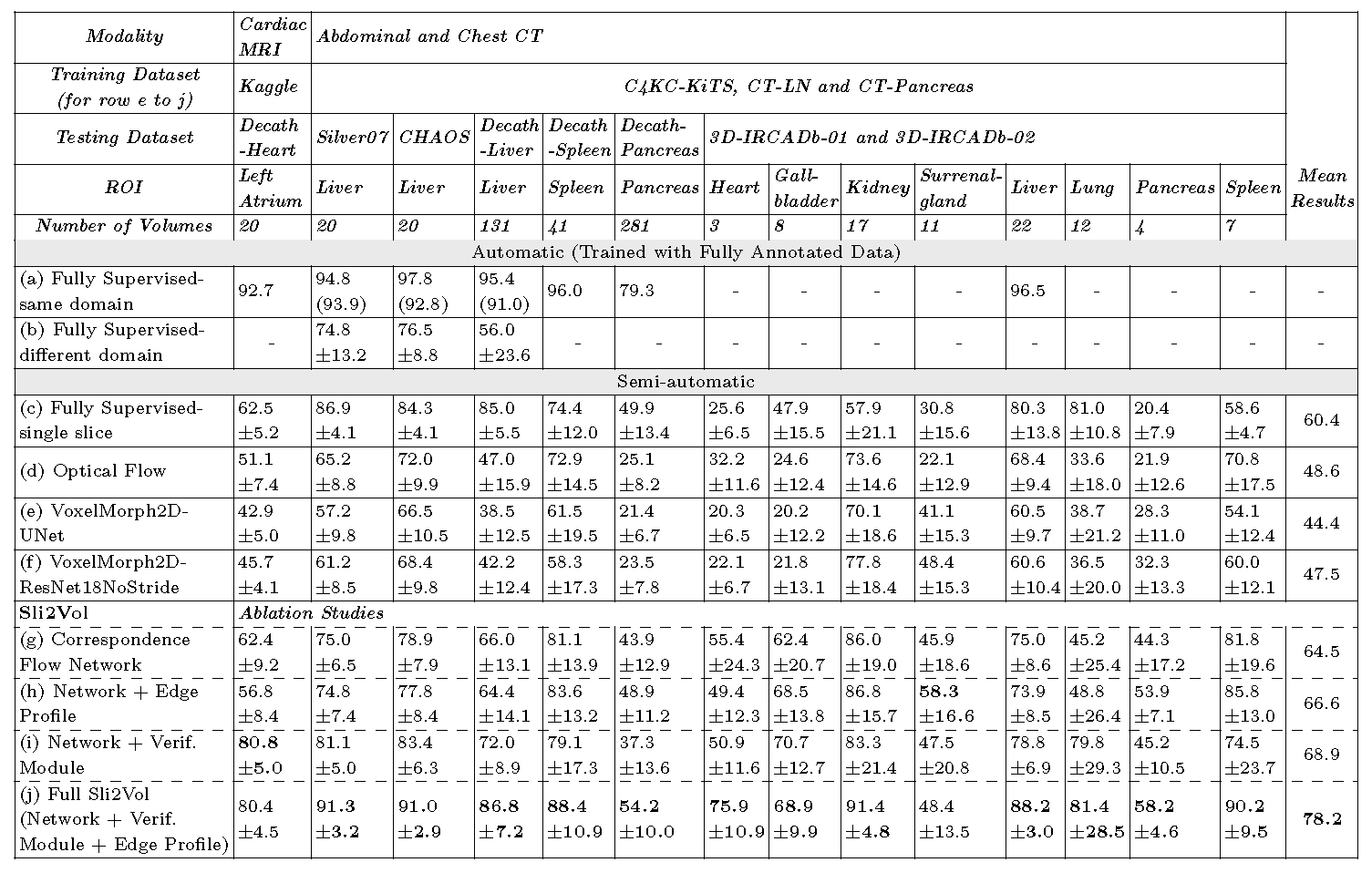
on 8 public datasets (both CT and MRI scans), spanning 9 different SOIs.
Without any parameter-tuning,
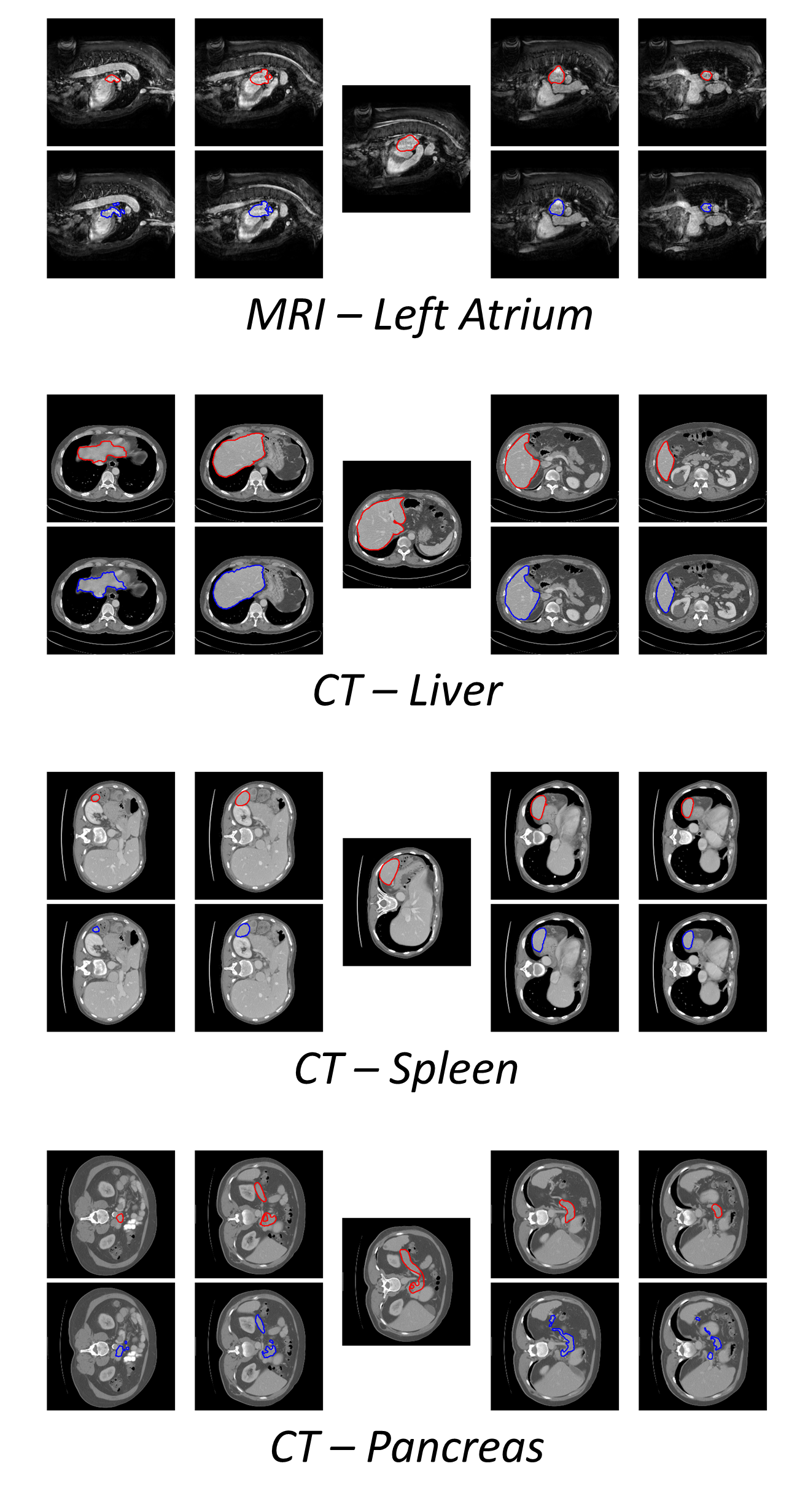
the same model achieves superior performance with Dice scores (0-100 scale) of over 80 for most of the benchmarks, including the ones that are unseen during training.
Our results show generalizability of the proposed approach across data from different machines and with different SOIs:
a major use case of semi-automatic segmentation methods where fully supervised approaches would normally struggle.
The source code will be made publicly available.
|